
If you're working in asset-heavy industries like utilities, oil and gas, chemicals, or manufacturing, you've probably heard some version of this pitch:
"Before you can start using AI, you need to build a complete Industrial Knowledge Graph. Connect every system, reconcile all your data, and create one unified copy of your entire operation. Once that foundation is 100% complete, then AI will work."
It sounds logical. It is also why, two years and several million dollars later, many organizations still have reliability engineers pulling data from six different systems, manually cross-referencing asset IDs in spreadsheets, and waiting for the “foundation” to be ready.
The foundation is never ready, and not because teams failed to execute, but due to a major flaw in the premise of the plan.
The Problem Isn’t the Technology. It is the Sequence.
Let’s be clear: the contextualization work is valuable. Connecting your P&IDs and asset hierarchy to historian tags, linking maintenance records to equipment models, mapping operational data to engineering documents – these matter. AI needs context to be useful.
But here’s what has changed: requiring 100% completion before use is no longer a technical constraint. It is an outdated assumption.
That requirement made sense when AI meant rigid machine learning (ML) models that needed everything encoded upfront. Modern large language models (LLMs) work differently. They can reason across partial information while operating within your business’s guardrails. The underlying technical constraints have shifted (more on the mechanics of this below).
This opens a different path: contextualization work is still required, but organizations can start using AI on real workflows in weeks.
What "Industrial Knowledge Graph" has come to mean
"Industrial knowledge graph" has become an overloaded term. Sometimes it means a literal graph database with nodes and edges. Sometimes it is shorthand for any unified data layer that connects systems.
Either way, what organizations often sign up for is a big, open-ended "connect all the data to everything" effort that goes well beyond what is actually required. The scope balloons. The timeline extends. And the original goal, getting AI to help your teams do their jobs better, gets pushed to “Phase 5” or “next fiscal year”.
The pattern looks like this:
- Strong underlying technology. Graph databases, ontology modeling tools, data integration platforms; these are legitimate, well-engineered systems.
- Over-broad default scope. The implementation approach assumes you need to model your entire operations before any piece of it becomes useful.
- Value deferred indefinitely. Teams keep waiting for the graph to be “ready” while manually logging into EAM, CMMS, APM, and PI to pull data and build the same reports they’ve been building for years.
- Friction also shows up in practice. The graph requires a new platform and new skills to operate. Time to first useful workflow stretches on while teams continue exporting data and rebuilding logic in spreadsheets.
A Different Path: The Semantic AI Layer
There is an alternative architecture that inverts the sequence, one designed specifically for how AI agents need to operate in industrial environments.
We call it the Semantic AI Layer.
Here is the core idea: instead of building a complete static knowledge graph as a prerequisite, you build a dynamic layer that gives AI agents the context they need to reason about your operations.
What the Semantic AI Layer Does
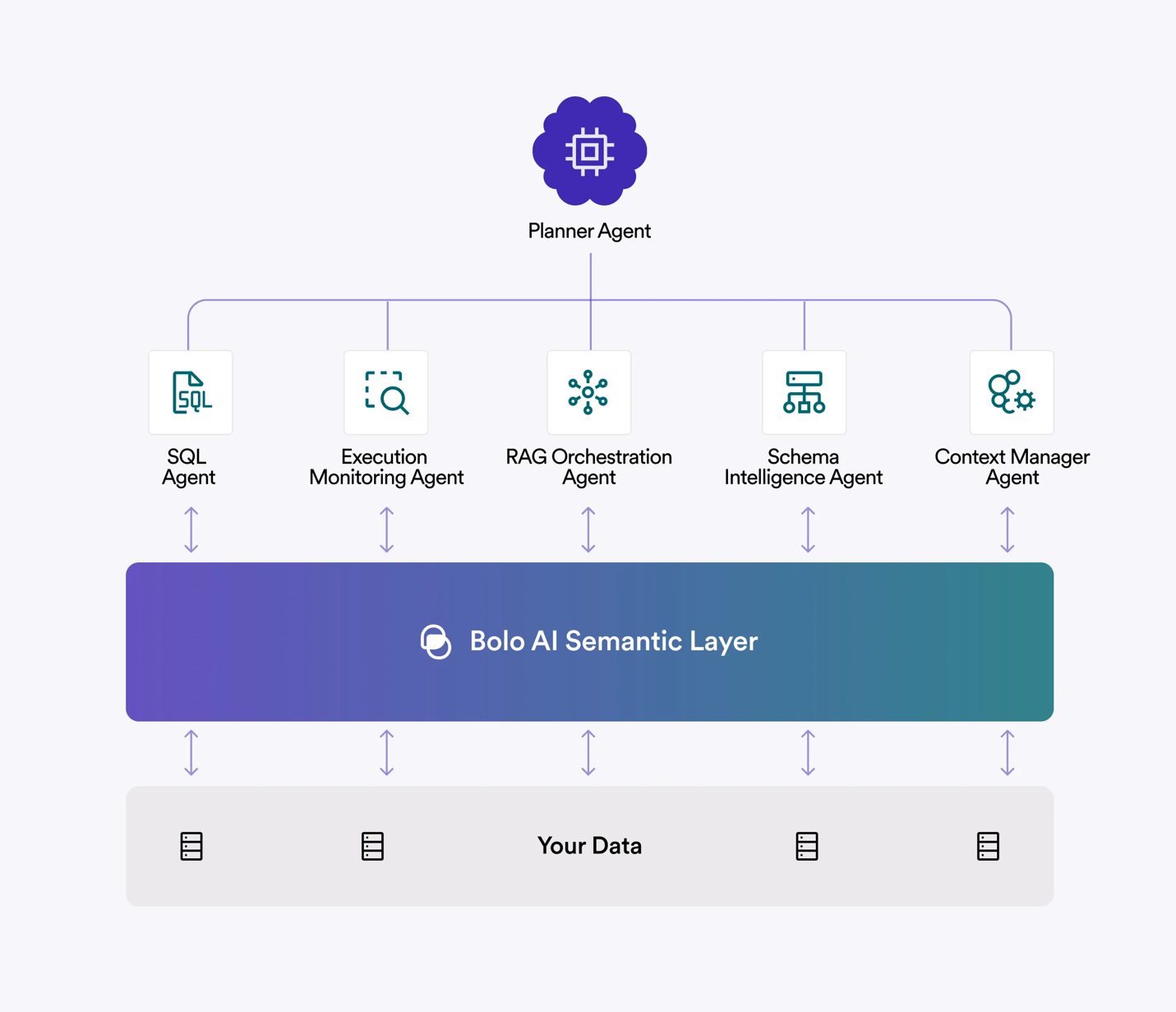
Think of it as a business glossary and rulebook that sits between AI and your existing systems. Unlike traditional semantic layers focused solely on metrics and dimensions, Bolo's Semantic AI Layer encompasses operational knowledge, dynamic context retrieval, and continuous learning. It doesn't make a complete copy or replace your data. It defines what things mean, where they live, and how they relate to each other so AI can interpret questions and take action without needing a new, rigid copy of every system directly.
The Semantic AI Layer combines three things:
- Codified industrial knowledge. Pre-built understanding of how your energy and industrial operations work. E.g., what a historian tag represents, how P&IDs map to equipment hierarchies in different enterprise systems, what patterns in operational data typically indicate. This isn’t generic LLM knowledge: it is domain-specific context built for your organization’s systems, terminology, and workflows.
- Adaptive context retrieval. Rather than requiring all connections to be explicitly mapped upfront, the layer can retrieve and assemble context dynamically. When an agent needs to understand a specific asset’s history, it pulls from available sources, structured and unstructured, and reasons across them based on the codified industrial knowledge.
- Progressive enrichment. As agents operate, the semantic layer is progressively enriched through use, with subject matter expert (SME) validation. Connections that get used frequently become more robust. Gaps that cause problems get flagged for attention. The layer expands the semantic coverage over time, guided by actual workflows rather than theoretical data modeling exercise.
Figure 1: Bolo AI Semantic Layer Architecture
What This Means in Practice
Currently, many reliability teams spend hours every week pulling together information for root cause analysis by querying the historian, checking maintenance logs, cross-referencing asset specs, or searching through old incident reports.
With a Semantic AI Layer, AI agents are deployed on that workflow using the data sources that already exist. The agents don't need a perfect, fully reconciled knowledge graph. This Semantic AI Layer on top of existing systems that defines your core entities (assets, sites, work orders, events, sensors), encodes relationships (what belongs to what, where data for each entity lives), and captures your KPIs and rules (MTBF, downtime, risk scores, backlog, "bad actor" definitions). In short, the semantic layer gives AI agents enough structured and codified context to navigate your systems, understand your terminology, and reason about your assets.
As the agents operate, gaps and patterns are surfaced for SME review, progressively enriching the semantic layer. Maybe certain historian tags get reliably associated with specific equipment. Maybe particular document types prove most useful for certain failure modes. This knowledge accumulates, making the agent more precise over time.
So, when a user asks questions in plain language: "Which transformers at Site A are highest risk this month and why?" or "Draft a work order for this alarm with the right asset, job plan, and parts" - the AI knows where to find the data, how to interpret it, and what rules to apply. It pulls from the right systems, applies the right logic, and delivers answers or takes actions, all without the user needing to know which system holds what.
The result: you start getting value in weeks, not years.
Why This Works Now (The Technical Shift)
For readers who want to understand the underlying mechanics:
The Flexibility of LLMs and Agents
Traditional ML approaches required structured, labeled, complete datasets because the models learned statistical patterns from that specific data. Gaps meant blind spots. Inconsistencies meant errors. A knowledge graph made sense as the prerequisite. You needed to encode everything the model would ever need to know.
Large language models changed part of that equation. They can reason across partial information, handle ambiguity, follow complex instructions and adapt their approach based on context. And when you architect them as agents, AI systems that can take actions, query data sources, and iterate toward an answer, they become capable of navigating complex workflows rather than just answering static questions.
This flexibility is what makes the "start now, enrich over time" approach technically possible. An agent doesn't need every relationship pre-mapped; it can work with available context and surface gaps as it encounters them.
LLMs Don't Understand Industrial Data
But here's what LLM flexibility doesn't solve: these models have no idea what your data actually means.
LLMs were trained on internet text - books, articles, websites, code repositories. They understand general concepts and common terminology. What they weren't trained on is the operational data that lives inside your historian, your CMMS, your APM system.
Consider a simple example. Your organization might use "probability of failure" in one system, "degradation score" in another, and "condition score" in a third, all referring to essentially the same concept, just calculated or labeled differently across tools. An LLM has no way to know these are equivalent. It has never seen your naming conventions, your tag structures, your internal terminology.
This is why generic LLM deployments struggle in industrial environments. The model is flexible and capable, but it is operating without the domain knowledge and context it needs to interpret what it is seeing.
How the Semantic AI Layer Bridges the Gap
The Semantic AI Layer solves this by providing codified industrial context the domain-specific knowledge that lets AI agents actually understand your data. It is a structured layer that captures:
- Equivalence mappings. The layer knows that "probability of failure," "degradation score," "condition index," and "health score" can refer to the same underlying concept and can normalize across these when an agent queries multiple systems.
- Tag interpretation frameworks. Rather than treating historian tags as opaque strings, the layer encodes the naming conventions and relationships that let agents parse meaning from tag structures, building understanding that can be extended as new patterns are identified.
- Operational context models. Working with your SMEs, the layer can be configured to understand how equipment behaves differently across operating modes, that certain thresholds matter more than others, and that temporal patterns often matter more than absolute values.
- Cross-system entity resolution. When an agent needs to connect a work order to a historian tag to an engineering document, the semantic layer enables the mappings, established during implementation and enriched through use, that make that connection possible.
The result: agents that can actually understand context and reason about your operations, not just process text. They understand that when a reliability engineer asks about "compressor performance issues," they need to pull from vibration data, maintenance history, and operating parameters, even if those live in different systems with different naming conventions.
Your data will never be perfect, and that's okay
The old story:
"Our data is too messy. Before we can do anything with AI, we need a multi-year effort to clean and centralize everything."
The industrial reality:
Multiple systems with inconsistent names. Free-text failure codes and maintenance notes. P&IDs as the de facto source of truth, often literally on paper or in PDFs. Human-entered SAP text like "pump was fixed" that will never be perfectly standardized.
Our stance:
Organizations don't need to wait for a utopian, perfectly clean, centralized dataset. Waiting for that perfection means never starting.
Our semantic layer and agents are designed to work with the data you have, messy tags and free text included. We don't need 100% coverage to get started. We work with subject matter experts to understand your systems, define the rules and mappings that matter for your workflows, and codify what we learn into agent-friendly rules so the system gets better over time.
We expect messy data. We focus on the data needed for specific workflows, and we improve structure only where it actually changes decisions.
And, if you already have a knowledge graph, it is not wasted.
In Bolo's architecture, that graph becomes another high-quality source behind the semantic layer. Agents still use the same tools and semantics whether the backing data lives in SQL, in a graph, or both. The graph becomes one of the tools, not the project.
The key difference: the graph, if organizations have one, should be a component in service of the semantic AI layer, not a prerequisite that blocks everything else.
The Real Questions to Ask Vendors
When someone pitches you on "building the knowledge graph first," ask this:
"What will my team be able to do in 30 days that they can't do today?"
If the answer is "we'll have started the data modeling work" or "we'll be further along on the integration architecture", that's infrastructure. Infrastructure is necessary, but it's not value.
If the answer is "your reliability engineers will have an AI agent that pulls together context for root cause analysis, saving them hours per incident", that's a workflow. That's something you can evaluate, measure, and build on.
The organizations making real progress with AI in heavy industry aren't the ones with the most complete data foundations. They're the ones who found a way to start delivering value with the enterprise systems they already have and while the foundation continues to develop.
A simple next step
Pick one real workflow like:
- High-risk asset reporting
- AI-assisted work order drafting
- Root cause analysis for a critical asset class
See what a semantic AI layer plus agents can do on your own data in weeks.
That's how you find out whether you actually need to build a massive graph first, or whether you can start delivering value this quarter with the systems you already have.
Want to explore what this looks like for your operations? Let's talk →




